
Searching websites and pages for information is a web robot’s main task. They put forth a lot of effort to gather information for search engines and other applications. Some people have valid reasons to keep certain pages off of search engines. Whether you want to modify how people can access your website. Or you wish to work on a development site hidden from Google search results. Once set up, the robots.txt file informs web spiders which content they can collect data from.
Create a Robots.txt File
The robots.txt file can be used on a page(s) or a whole site, and it is one of the first things crawlers look at. to prevent search engines from displaying information about your website. We’ll explain how to use the robots.txt file in this article, along with the syntax required to fend off these bots.
User-agent: *
Disallow: /
Let’s dissect the following code. The term “user-agent” refers to web crawlers, and the asterisk (*) designates all web crawlers. As a result, the first sentence, “Listen up all web crawlers!”, draws the reader’s attention. We next go to our second line, which indicates to the web crawler where to go. The forward slash (/) prevents search engines from crawling every page on your website. In this situation, you can also oppose information gathering for a particular page. It shows the arrangement of our buildings. Given that our building’s design does not require searchability, use the command below. I can instruct all bots to omit the buildinglayout.png photo’s index while still making it accessible to any visitor who requests to see it.
User-agent: *
Disallow: /buildinglayout.png
Contrary, if you would like for all search engines to collect information on all the pages in your site you can leave the Disallow section blank.
User-agent: *
Disallow:
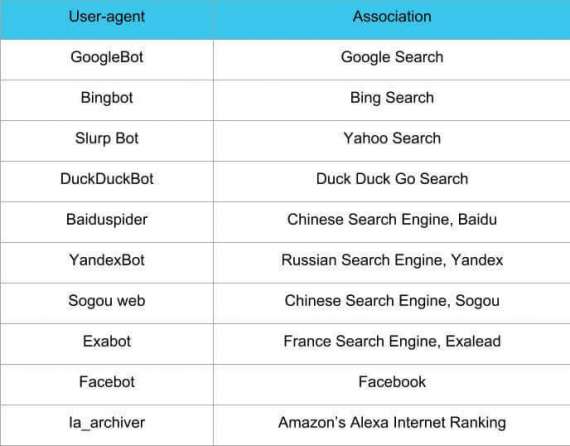
Web crawlers, also known as user-agents, come in a variety of forms. The most well-known web crawlers are listed below in a graph along with their associations. Additionally, you can tell these bots to index a certain page by using the Allow command, as seen in the example below. These web crawlers can be added to your robots.txt file in the following ways:
User-agent:Googlebot
Allow: /parkinglotmap.png
Disallow: /buildinglayout.png
You can make a robots.txt file using a text editor, upload it to your root directory, or any other directory, as most websites don’t come with one automatically (and it’s not necessary). Fortunately, there is a place in the admin window where you may generate a robots.txt file if you use the well-liked CMS WordPress and its helpful SEO plugin Yoast.
Robots.txt File In WordPress
After logging into your WordPress backend (yourdomain.com/wp-login.php) locate the SEO section and select Tools.
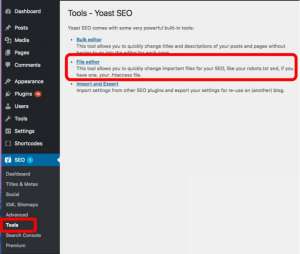
After clicking on the file editor link, you see a page that looks similar to the code used in the first of our article.
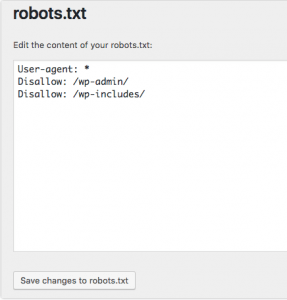
Our example prevents web bots from accessing the wp-includes directory and the WordPress login page while still enabling people and bots to view other pages on our website. Remember to add the required finishing slashes to the directory after it (but not needed when disallowing pages). To activate the robots.txt file after editing, pick the “save changes to robots.txt” option.
